Bean数据集
教学视频
说明
Bask Report支持Bean数据集,所谓Bean数据集就是指你可以在当前的BaskReport集成Java项目中利用JavaAPI为Dataset提供Bean类型的数据源。
如果数据是可以通过Restful接口获取的,那么我们强烈建议你使用统一数据源中的API数据源代替Bean数据集
Bask Report基于java.util.ServiceLoader机制支持自定义的Bean数据源,对应的抽象类:
public abstract class BeanDataset extends Dataset {
public BeanDataset() {
super(null,null);
}
/**
* @param context 上下文对象,从中可以获取报表参数,和需要的单元格值
* @return 返回数据集数据
*/
public abstract List<?> getData(BeanContext context);
/**
* @return 返回当前数据集在计算时需要依赖的单元格名称,如果不依赖单元格返回null或空的List
*/
public abstract List<String> getDependCells();
/**
* @return 返回当前数据集名称,不能返回空
*/
protected abstract String name();
/**
* @return 返回当前数据集对应的字段集合,不能为空
*/
public abstract List<Field> getFields();
@Override
public final String getName() {
return name();
}
}
全路径为:com.basksoft.report.core.model.dataset.BeanDataset
其中BeanContext提供了名称为parameters的报表参数集合变量,可用于查询过滤数据的参数判断,参数的定义可以参考:报表参数
前期准备-ServiceLoader定义
分下面几个步骤来使用:
在resources资源目录下创建META-INF/services文件夹
在services文件夹中创建文件,以接口全名命名,就是:com.basksoft.report.core.model.dataset.BeanDataset
创建接口实现类,参考代码
public class TaskDataset extends BeanDataset { @SuppressWarnings("unused") private static int number = 1; @Override public List<?> getData(BeanContext context) { List<Map<String,Object>> datas=new ArrayList<Map<String,Object>>(); Map<String, Object> data = new HashMap<String, Object>(); data.put("collectionAll", RandomUtils.nextInt(5000000)); data.put("category1", RandomUtils.nextInt(30)); data.put("category2", RandomUtils.nextInt(3000)); data.put("category3", RandomUtils.nextInt(30)); data.put("category4", RandomUtils.nextInt(30)); data.put("category5", RandomUtils.nextInt(30)); data.put("category6", RandomUtils.nextInt(300000)); datas.add(data); return datas; } @Override public List<String> getDependCells() { return null; } @Override protected String name() { return "执行任务统计"; } @Override public List<Field> getFields() { List<Field> fields = new ArrayList<Field>(); fields.add(new Field("collectionAll", "统计所有", FieldType.Integer)); fields.add(new Field("category1", "分类1", FieldType.Integer)); fields.add(new Field("category2", "分类2", FieldType.Integer)); fields.add(new Field("category3", "分类3", FieldType.Integer)); fields.add(new Field("category4", "分类4", FieldType.Integer)); fields.add(new Field("category5", "分类5", FieldType.Integer)); fields.add(new Field("category6","分类6", FieldType.Integer)); return fields; } }
- 修改META-INF/services下的com.basksoft.report.core.model.dataset.BeanDataset文件
xxx.xxx.xxx.TaskDataset
设计器使用
在数据源设置面板中,选择第一个数据集标签页,并单击添加按钮:
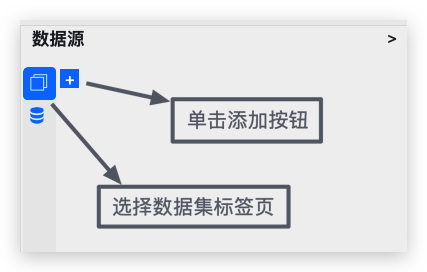
在弹出菜单中选择创建自定义Bean数据集:
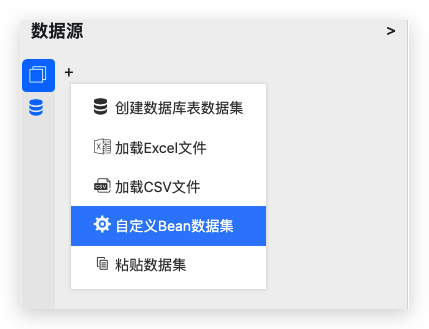
在弹出向导窗口中选择需要添加的Bean数据集对象:
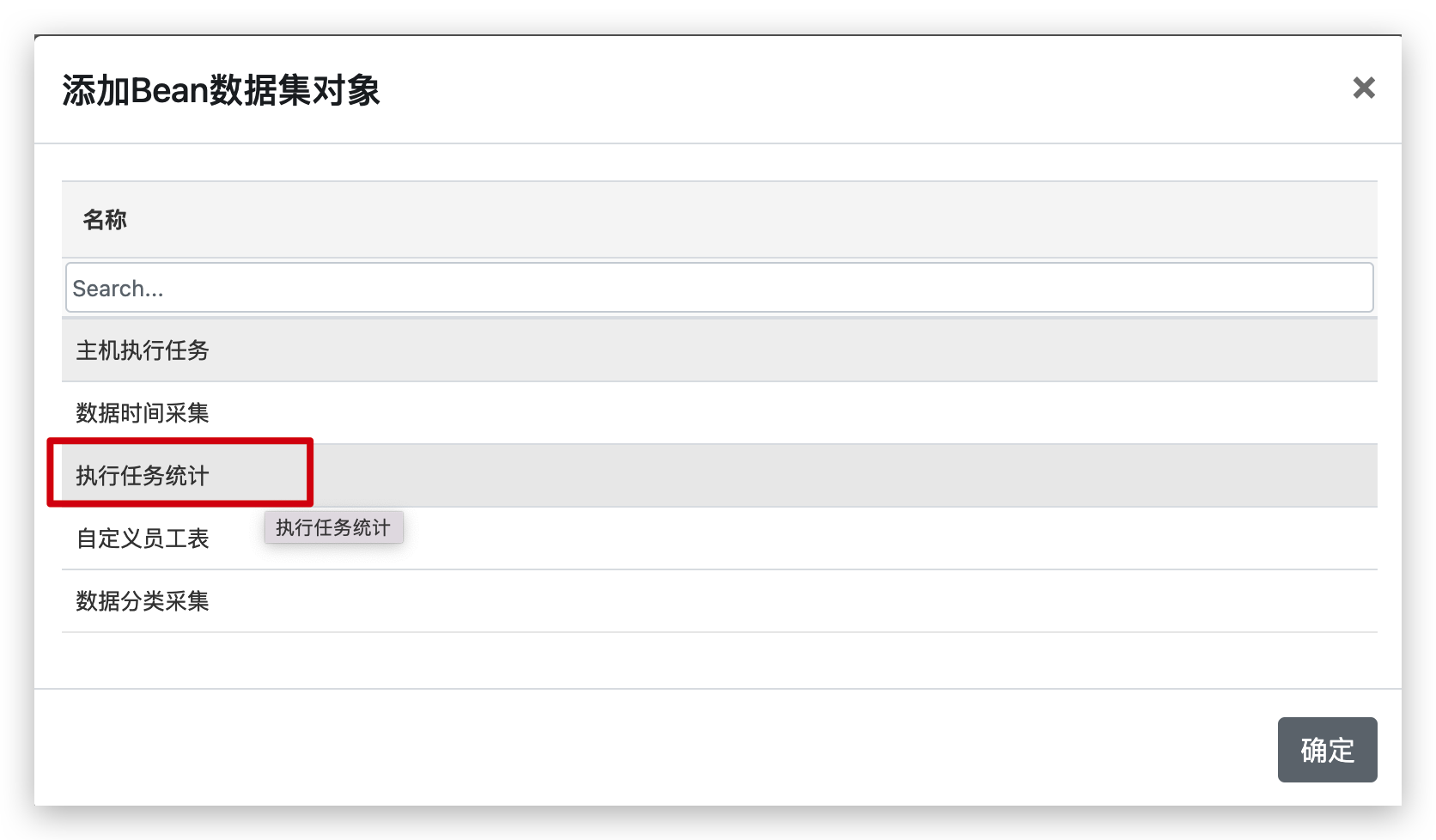
选中Bean数据集对象,并单击确定按钮。就完成了Bean数据集的添加。
注意事项
如果项目整合了Spring,需要注意的是在【SPI】创建这个ServiceLoader的时候,Spring还未完成初始化,所以以下的用法并不是你想想的那样可以生效的:
public class TaskDataset extends BeanDataset {
@SuppressWarnings("unused")
private static int number = 1;
//spring中的annotation标记不会起作用
@Value("smtp.user")
private String smtpUser;
//spring中的annotation标记不会起作用
@Autowired
private DataService dataservice;
//直接通过Spring的ApplicationContext获取Bean也是不行的
private UserService userService = SpringUtils.getBean(UserService.class);
...
}
正确的做法应该是在方法的内部去访问Spring的资源,例如:
public class TaskDataset extends BeanDataset {
@SuppressWarnings("unused")
private static int number = 1;
@Override
public List<Field> getFields() {
FieldService fieldService = SpringUtils.getBean(FieldService.class)
...
}
...
}