单元格过滤数据集
概述
在使用SQL类型的数据集,定义具体SQL时,可以在SQL中通过表达式引用具体的单元格,以实现利用单元格数据过滤数据集中数据的功能。
比如下面的例子:
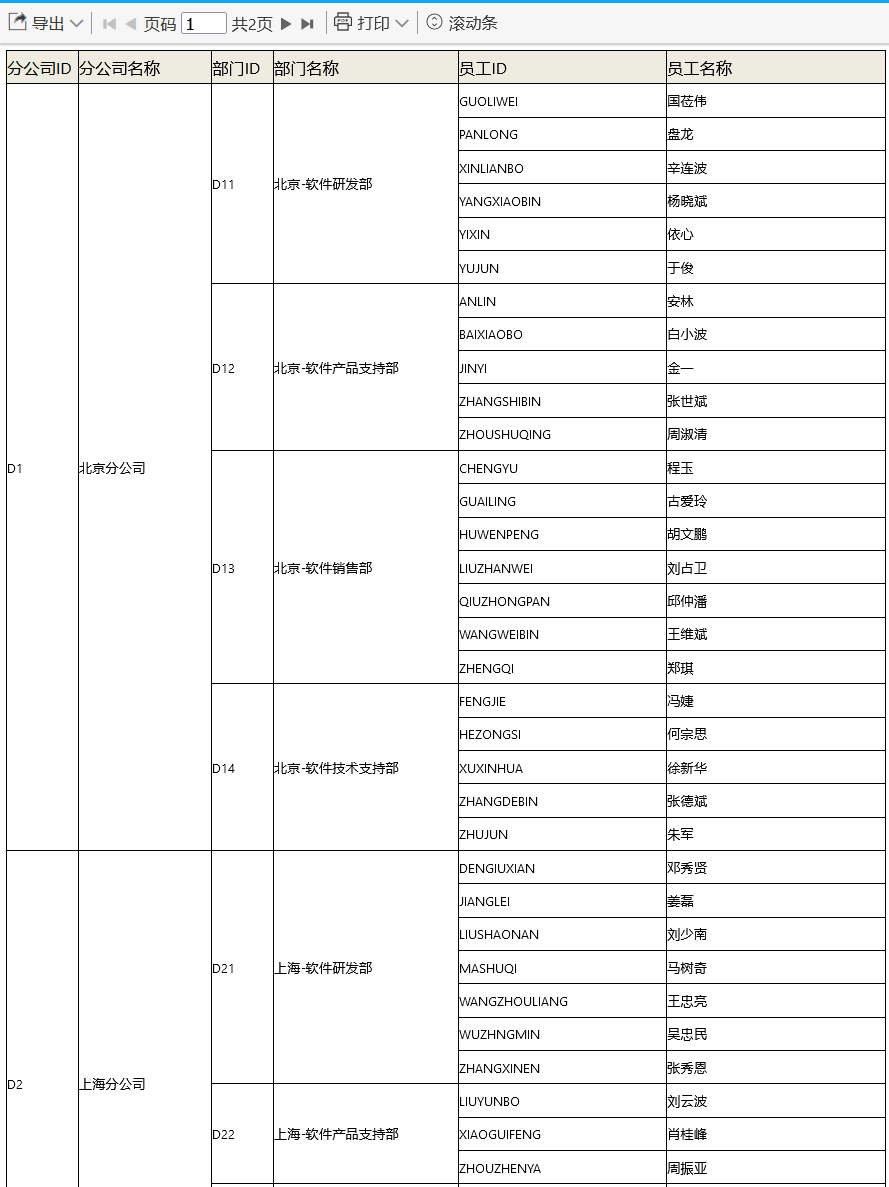 ]
上面的例子中,第一、二列,为branch数据集中的两个字段;第三、四列为dept数据集的两个字段;第五、六列为employee数据集的两个字段。这其中branch数据集获取的是所有数据,而dept和employee数据集则是利用在SQL中依赖单元格名称实现数据集的过滤功能,从页实现我们现在看到的三层数据的分组显示功能,下面我们就来具体看下这个功能是如何使用的。
]
上面的例子中,第一、二列,为branch数据集中的两个字段;第三、四列为dept数据集的两个字段;第五、六列为employee数据集的两个字段。这其中branch数据集获取的是所有数据,而dept和employee数据集则是利用在SQL中依赖单元格名称实现数据集的过滤功能,从页实现我们现在看到的三层数据的分组显示功能,下面我们就来具体看下这个功能是如何使用的。
定义SQL数据集
branch数据集
先来看看branch数据集的定义,截图如下:
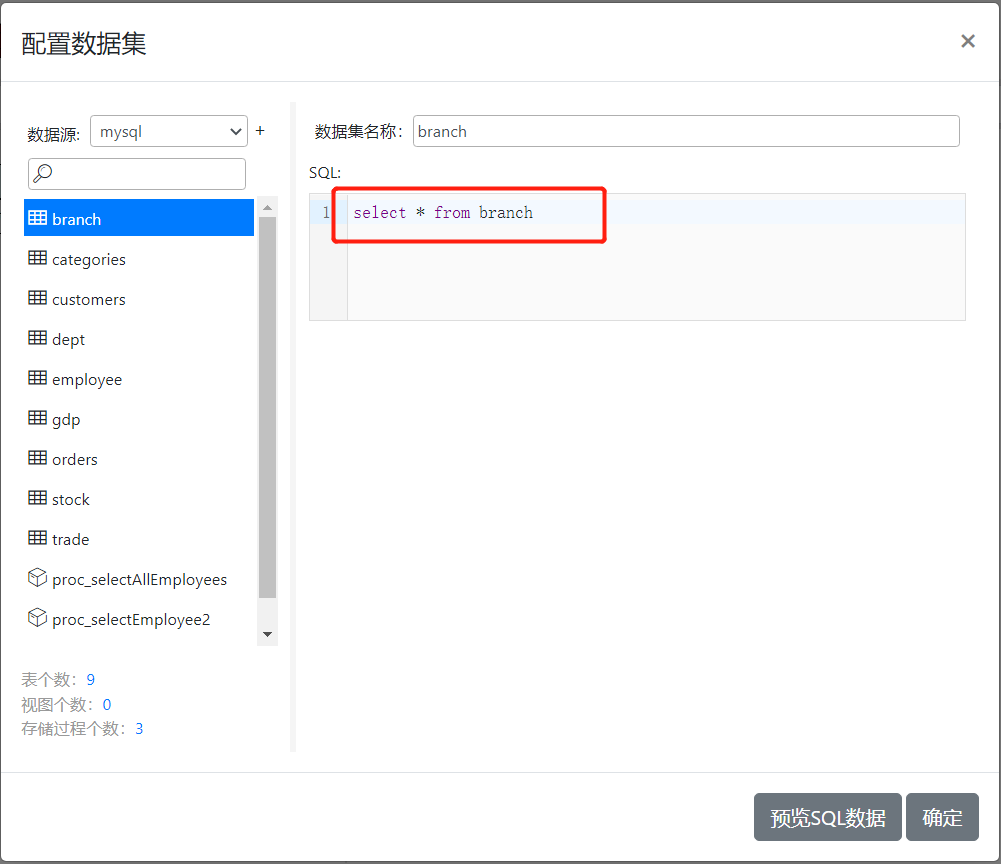 可以看到,branch数据集就是获取branch表中所有数据,不对数据进行过滤处理。
可以看到,branch数据集就是获取branch表中所有数据,不对数据进行过滤处理。
dept数据集
dept数据集定义截图如下:
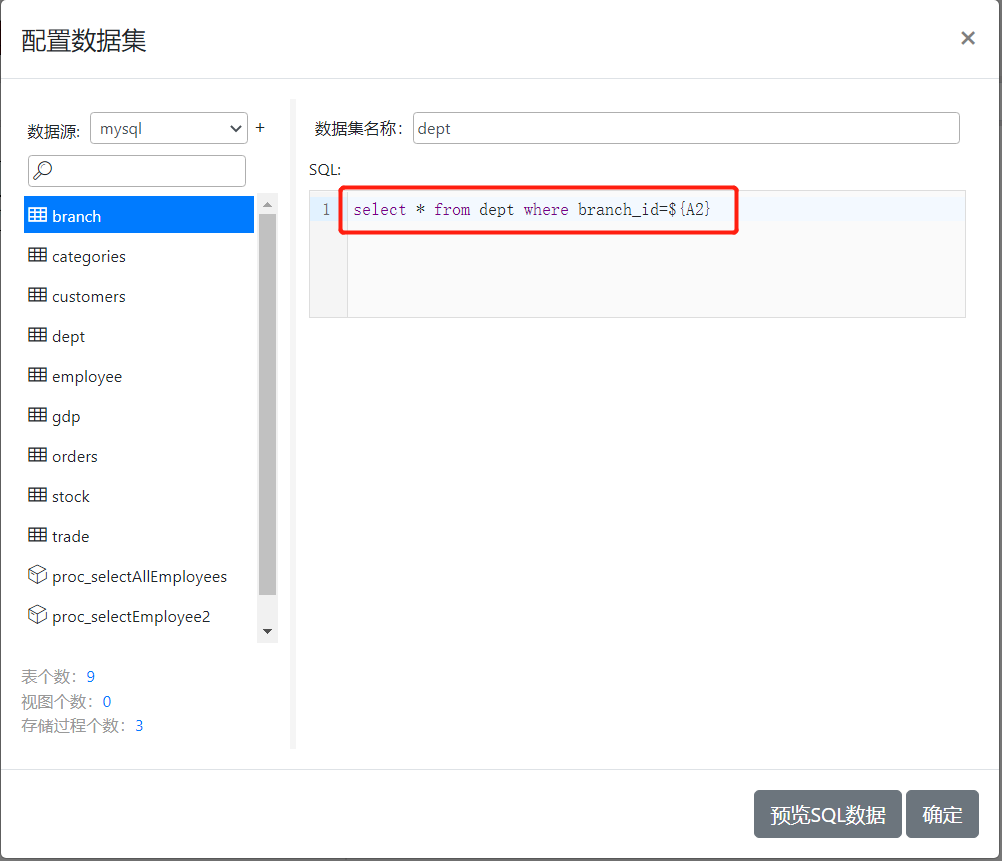
dept数据集对应的SQL为:
select * from dept where branch_id=${A2}
在这个SQL当中,我们添加了一个条件branch_id=${A2},就是将branch_id的值限制为A2单元格的值,我们知道,在BaskReport当中,SQL中使用表达式需要放在${}符号中,所以上面的A2就表示取A2单元格的值。 数据集在定义的时候实际上不会依赖于任何单元格,所以必须要将dept数据集中对应的字段绑定到具体的单元格,那么dept数据集SQL中对应的条件要获取A2单元格的值才可行。所以我们在预览这个数据集的数据时,会看到返回的是一个空的列表。
employee数据集
与dept数据集定义方式类似,截图如下:
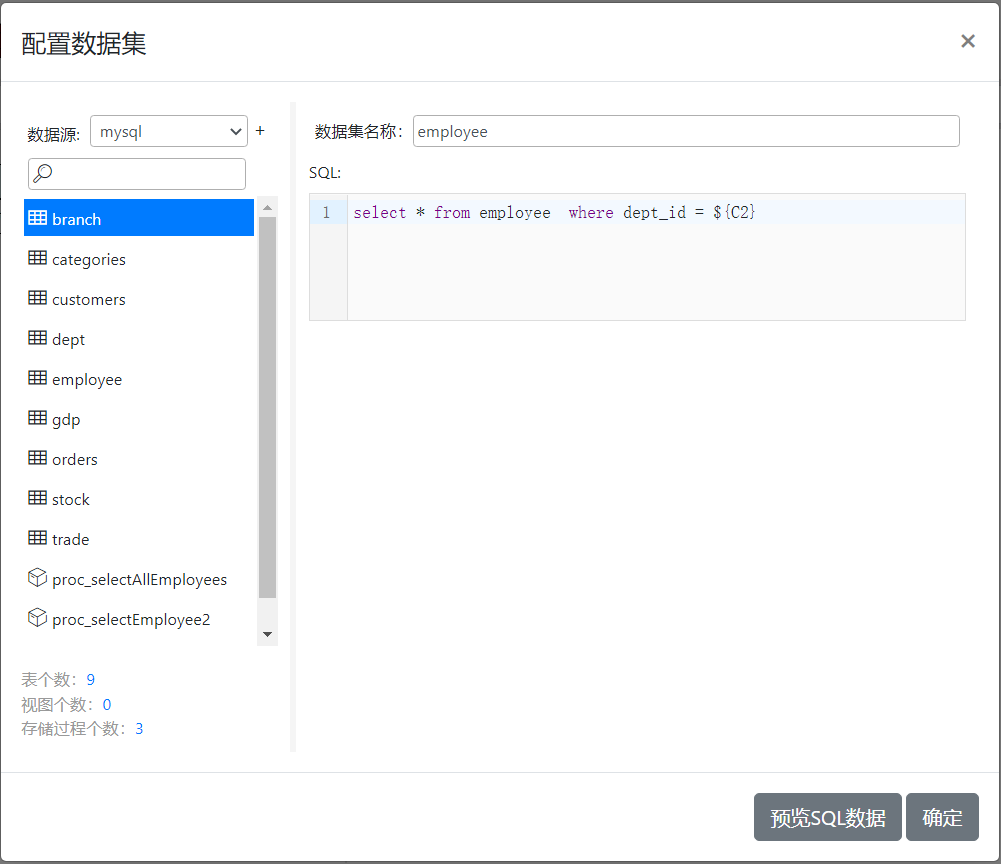 在employee数据集中,SQL中添加的条件是dept_id=${C2},同样就表示其字段在绑定具体单元格时,将依据当前单元格所在位置取C2单元格的值来作为dept_id字段的过滤条件值。
在employee数据集中,SQL中添加的条件是dept_id=${C2},同样就表示其字段在绑定具体单元格时,将依据当前单元格所在位置取C2单元格的值来作为dept_id字段的过滤条件值。
设计报表
设计好的报表模版如下图所示:
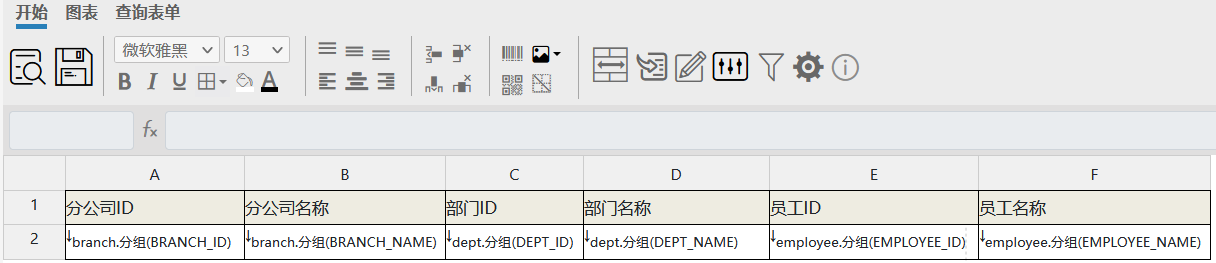 可以看到,在A2单元格绑定的是branch数据集的branch_id字段,C2单元格绑定的是dept数据集的dept_id字段;这样,在处理C2单元格时因为还未加载过dept数据集,所以会尝试加载这个数据集中的数据,但在加载dept数据集中数据时,对应的SQL要求取A2单元格的值作为branch_id字段的过滤条件(branch_id=${A2}),C2单元格会根据自己所在位置取到的A2单元格的值,就是branch数据集下branch_id字段展开后的值,所以可以实现根据A2单元格的值来过滤C2单元格的值。
可以看到,在A2单元格绑定的是branch数据集的branch_id字段,C2单元格绑定的是dept数据集的dept_id字段;这样,在处理C2单元格时因为还未加载过dept数据集,所以会尝试加载这个数据集中的数据,但在加载dept数据集中数据时,对应的SQL要求取A2单元格的值作为branch_id字段的过滤条件(branch_id=${A2}),C2单元格会根据自己所在位置取到的A2单元格的值,就是branch数据集下branch_id字段展开后的值,所以可以实现根据A2单元格的值来过滤C2单元格的值。
同样E2单元格绑定的是employee数据集的employee_id字段,employee数据集中的SQL要获取C2单元格的值来作为入参过滤数据,同样又因为C2单元格绑定的是dept数据集的dept_id字段,所以通过E2单元格就可以取到相对于E2单元格的C2单元格值作为employee数据集中的SQL的入参条件值。
保存预览,就可以看到之前截图后的效果。
数据重新加载数据的原则
上面的例子中,D2单元格绑定的是dept数据集的dept_name字段,它的左父格是C2,所以D2会在C2计算完成后再计算,又因为D2单元格和C2单元格绑定的数据集相同,所以D2单元格会直接从其左父格C2单元格中获取dept数据集的dept_name字段的值,而不会重新计算dept数据集的值来填充D2单元格。同理,对于F2单元格也是这样。
对于SQL类型的数据集依赖单元格值为条件过滤数据的情况,要求这种数据集的字段必须要与单元格绑定,运行时会根据绑定单元格的父格关系来查找SQL中引用的目标单元格的值,如果找不到目标单元格,那么就会产生单元格找不到的错误。
适用场景
这种关联具体单元格的SQL数据集适合于主从结构的报表,特别是从表的数据量特别大的情况。对于从表数据量特别大的情况如果采用本章中介绍的表达式过滤、数据集过滤之类的方法实现,那么首先可能会占用大量的内存,因为这些方法都需要将从表数据全部加载到内存,再根据报表单元格中配置的条件过滤数据,另一方面可能会导致性能问题,因为过滤时中需要迭代从表中所有数据。
凡事有利必有弊,这种在数据集SQL中关联单元格实现数据过滤的方式,将数据过滤的工作交给数据库去完成,会产生大量的查询,以本小节中的三级主从表为例,最终查询数据库的次数由C2和E2单元格的数量决定,所以上面的示例中,数据库的查询总次数=branch数据集一次+C2单元格的数量+E2单元格的数量。
综上,在这种SQL中关联单元格实现从表数据过滤报表中,SQL中的条件部分对应的字段最好是建好相关索引,以防止多次查询对数据库的压力过大。
在Bean数据集中使用单元格参数
在BaskReport报表当中,除了可以在SQL数据集中使用单元格为入参外,在Bean数据集中也可以使用单元格参数,先来看看Bean数据集在定义的时候需要实现的四个方法:
/**
* @param context 上下文对象,从中可以获取报表参数,和需要的单元格值
* @return 返回数据集数据
*/
public abstract List<?> getData(BeanContext context);
/**
* @return 返回当前数据集在计算时需要依赖的单元格名称,如果不依赖单元格返回null或空的List
*/
public abstract List<String> getDependCells();
/**
* @return 返回当前数据集名称,不能返回空
*/
protected abstract String name();
/**
* @return 返回当前数据集对应的字段集合,不能为空
*/
public abstract List<Field> getFields();
这其中的第二方法getDependCells,就是要求我们在实现Bean数据集时指定依赖的单元格列表,当然如果没有依赖的单元格返回null或一个空的List就可以。
一旦我们在getDependCells方法中返回了需要依赖的单元格名称后,那么在运行获取数据的getData(BeanContext context)方法中,通过参数context中的getCellValue(String cellName)就可以取到对应的单元格的值,比如我们下面的一个实现:
@Override
public List<?> getData(BeanContext context) {
Object a1=context.getCellValue("A1");
Object b1=context.getCellValue("B1");
System.out.println("A1:"+a1);
System.out.println("B1:"+b1);
List<Map<String,Object>> datas=new ArrayList<Map<String,Object>>();
//...
return datas;
}
@Override
public List<String> getDependCells() {
List<String> list=new ArrayList<String>();
list.add("A1");
list.add("B1");
return list;
}
上面的实现中,我们在getDependCells()方法中返回A1和B1单元格,所以在getData方法中就可以通过context的getCellValue方法获取A1和B1单元格的值,当然是否能获取到对应单元格的值,还取决于当前数据集字段绑定的具体单元格位置,原理和上面介绍的SQL数据集原理相同,这里不再赘述。