计算字段
教学视频
概述
计算字段是指在数据集中存在的一种特殊类型的字段,这个字段的值可以通过表达式来定义,通过使用表达式可将当前数据集中已存在的字段进行组合计算,产生一个新的字段。在报表当中,所有类型的数据集都支持计算字段。
计算字段的优势:
| 对比项 | 在单元格写表达式 | 使用计算字段 |
|---|---|---|
| 复用性 | ❌ 每个单元格各写一遍 | ✅ 数据集层定义,多处共用 |
| 可维护性 | ❌ 修改需逐个单元格改 | ✅ 只需修改数据集中的字段定义 |
| 语义清晰度 | ❌ 单元格内嵌大段表达式 | ✅ 绑定有意义的字段名 |
| 是否需改数据库 | — | ✅ 完全不需要 |
计算字段定义
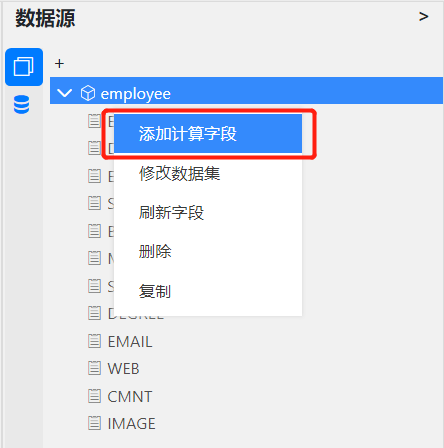
选择一个数据集,在数据集名称上点击右键,从弹出的菜单中选择添加计算字段,如下图:
在弹出窗口中输入字段名称和当前字段运行时采用的具体表达式内容,如下图:
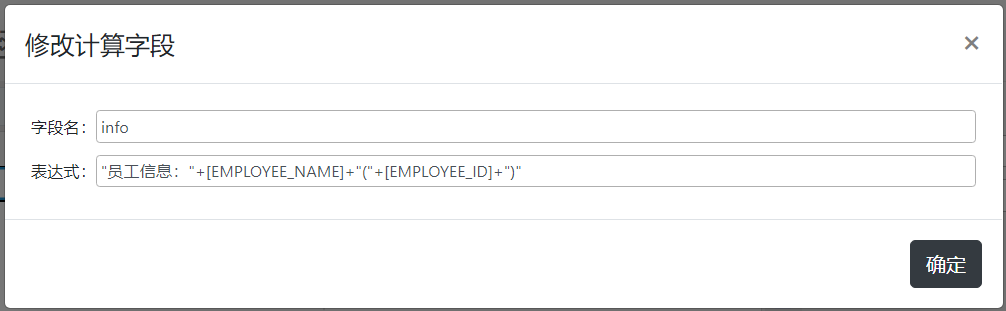
在这个名为info的计算字段当中,对应的表达式为:
"员工信息:"+[EMPLOYEE_NAME]+"("+[EMPLOYEE_ID]+")"
上面的表达式中,引用了当前数据集中的EMPLOYEE_NAME和EMPLOYEE_ID两个字段,在计算字段当中,如果需要引用当前数据集中其它字段,具体做法就是在字段名称外面添加一个[]包裹即可。
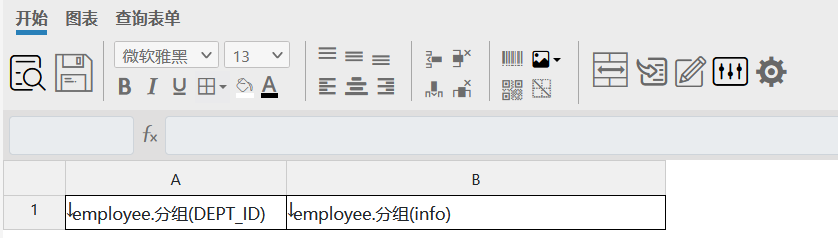
设计报表样式如下图:
保存预览,效果如下图所示:
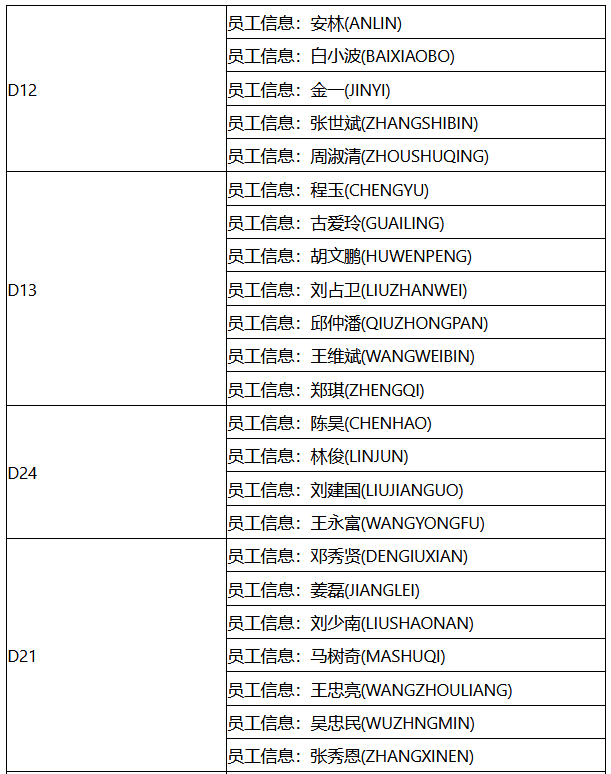
可以看到,B1单元格绑定的info字段中,根据当前行数据将表达式计算后的内容拼接后返回。
实际上,在计算字段中定义的表达式,除了可以引用当前字段所在数据集中其它字段外,还可以使用参数、函数之类的其它表达式信息,这样就使得计算字段的功能得以进一步增强。
如果在计算字段中引用其它单元格信息,那么运行时会根据当前计算字段所在单元格位置来引用目标单元格,这一点与单元格中定义的其它表达式运行时的计算方式相同。
表达式语法基础
引用当前数据集的其他字段
在计算字段的表达式中,用 [字段名] 的形式引用同一数据集的其他字段:
[字段名]
示例:引用 EMPLOYEE_NAME 和 EMPLOYEE_ID 两个字段:
"员工信息:" + [EMPLOYEE_NAME] + "(" + [EMPLOYEE_ID] + ")"
运行时每一行数据都会用实际值替换 [...] 中的字段引用,输出类似:员工信息:张三(E001)
引用报表参数
$参数名
示例:将参数 $year 拼入字段值中:
$year + "年度业绩:" + [REVENUE]
使用内置函数
计算字段中可以直接调用所有 BaskReport 内置函数,函数名不区分大小写。
常用场景与示例
场景 1:字段拼接(文本组合)
将员工姓名与部门名称拼接展示:
[EMPLOYEE_NAME] + " / " + [DEPT_NAME]
输出示例:张三 / 研发部
场景 2:数值计算(利润率)
根据收入和成本计算利润率,并格式化为百分比:
formatNumber(([REVENUE] - [COST]) / [REVENUE], "##.##%")
输出示例:35.50%
场景 3:条件判断(等级分类)
根据成绩返回等级标签:
if ([SCORE] >= 90) {
return "优秀";
} else if ([SCORE] >= 75) {
return "良好";
} else if ([SCORE] >= 60) {
return "及格";
} else {
return "不及格";
}
场景 4:日期处理(提取年份 / 计算工龄)
提取入职年份:
year([HIRE_DATE])
计算工龄(年):
datedif([HIRE_DATE], now(), "y") + "年"
输出示例:5年
场景 5:文本格式化(截取 / 转换)
截取前 10 个字符并添加省略号:
if (len([DESCRIPTION]) > 10) {
return left([DESCRIPTION], 10) + "...";
} else {
return [DESCRIPTION];
}
转换为大写:
upper([PRODUCT_CODE])
场景 6:空值处理(空值替换)
当字段值为空时显示默认文本:
if (isEmpty([REMARK])) {
return "暂无备注";
} else {
return [REMARK];
}
场景 7:数字格式化(千分位 / 人民币大写)
格式化为千分位显示:
formatNumber([AMOUNT], "#,##0.00")
转换为人民币大写:
rmb([AMOUNT])
输出示例:壹万贰仟叁佰肆拾伍圆
场景 8:结合参数动态生成内容
根据报表参数 $year 动态生成标题字段:
$year + "年 " + [DEPT_NAME] + " 部门报表"
计算字段在报表中的绑定
计算字段添加完成后,与普通字段使用方式完全一致:
在单元格表达式中按标准格式绑定:
数据集名称.聚合方式(计算字段名)
示例:
ds1.list(full_info) // 列表展开计算字段
ds1.list(profit_rate) // 展开利润率字段
注意事项
1. 字段引用格式
计算字段表达式中引用本数据集的其他字段,必须使用 [字段名] 格式,而非直接使用字段名,否则引擎无法识别为字段引用:
// ✅ 正确
[EMPLOYEE_NAME] + "(" + [EMPLOYEE_ID] + ")"
// ❌ 错误(会被当作未定义变量)
EMPLOYEE_NAME + "(" + EMPLOYEE_ID + ")"
2. 引用单元格时的位置依赖
如果计算字段中引用了报表单元格(如 A1),运行时会根据当前计算字段所在单元格的位置来确定目标单元格,与报表中其他表达式的行为一致,需注意父格影响。
3. 字段名建议
- 使用英文字母和下划线,避免中文字段名
- 取语义化名称,如
profit_rate、age_label,方便他人理解
4. 表达式返回值
多行脚本表达式须使用 return 语句显式返回最终值:
var label = "";
if ([SCORE] >= 60) {
label = "及格";
} else {
label = "不及格";
}
return label;
支持的内置函数速查
文本函数
| 函数 | 说明 | 示例 |
|---|---|---|
len(text) |
返回字符串长度 | len([NAME]) |
left(text, n) |
从左截取 n 个字符 | left([CODE], 3) |
right(text, n) |
从右截取 n 个字符 | right([CODE], 4) |
mid(text, start, n) |
从指定位置截取 n 个字符 | mid([CODE], 2, 3) |
upper(text) |
转大写 | upper([CODE]) |
lower(text) |
转小写 | lower([CODE]) |
trim(text) |
去除首尾空格 | trim([NAME]) |
replace(text, old, new) |
替换字符 | replace([TEXT], ",", ";") |
rmb(number) |
转人民币大写 | rmb([AMOUNT]) |
数学函数
| 函数 | 说明 | 示例 |
|---|---|---|
abs(number) |
绝对值 | abs([DIFF]) |
roundoff(number, scale) |
四舍五入 | roundoff([RATE], 2) |
floor(number) |
向下取整 | floor([VALUE]) |
ceil(number) |
向上取整 | ceil([VALUE]) |
formatNumber(number, pattern) |
数字格式化 | formatNumber([AMT], "#,##0.00") |
日期函数
| 函数 | 说明 | 示例 |
|---|---|---|
year(date) |
返回年份 | year([HIRE_DATE]) |
month(date) |
返回月份 | month([CREATE_TIME]) |
day(date) |
返回日 | day([BIRTH_DATE]) |
now() |
当前日期时间 | now() |
formatDate(date, pattern) |
日期格式化 | formatDate([DATE], "yyyy-MM-dd") |
datedif(d1, d2, unit) |
两日期差值 | datedif([HIRE_DATE], now(), "y") |
dateAdd(date, n, unit) |
日期加减 | dateAdd([DATE], 30, "d") |
判断函数
| 函数 | 说明 | 示例 |
|---|---|---|
isEmpty(expr) |
是否为空 | isEmpty([REMARK]) |
isNotEmpty(expr) |
是否非空 | isNotEmpty([VALUE]) |
isNull(expr) |
是否为 null | isNull([FIELD]) |