LOD 表达式
LOD 全称为 Level Of Detail,即详细级别,所以 LOD 表达式又称为详细级别表达式,它的作用就是让我们在限定的粒度下对一批数据进行计算分析。
在 BaskAdapt 当中,支持的 LOD 表达式有 Fixed、Partition、OrderBy 三个。
Fixed 表达式
语法:{Fixed [Field1],[Field2] : 聚合函数([Field)}
Fixed 表达式由两个用冒号分隔的表达式部分构成。
Fixed[字段]
这是第一部分,是可选的。这是您要为其计算值的0个或多个字段。
举例来说,如果要查找客户和区域的总销售额,请输入 Fixed [Customer ID], [Area]。如果未选择任何字段,这相当于执行在冒号右侧定义的聚合,并为每一行重复该值。
聚合函数([字段])
这是第二部分,该部分必须要由一个聚合函数构成,目前支持的聚合函数有 Count、CountD、Avg、Sum、Max、Min 等九个,具体可参考聚合函数部分的介绍。
该部分的作用就是根据第一部分的操作产生的结果集选择要计算的内容以及所需的聚合级别。举例来说,如果要查找总销售额,请输入 Sum([Sales],那完整的表达式就是
{Fixed [Customer ID],[Area] : Sum([Sales])}
创建示例
Fixed 表达式的结果是产生一批新的聚合数据,所以需要创建一个新的字段,可以点击工具栏上的创建计算字段实现,如下图所示:
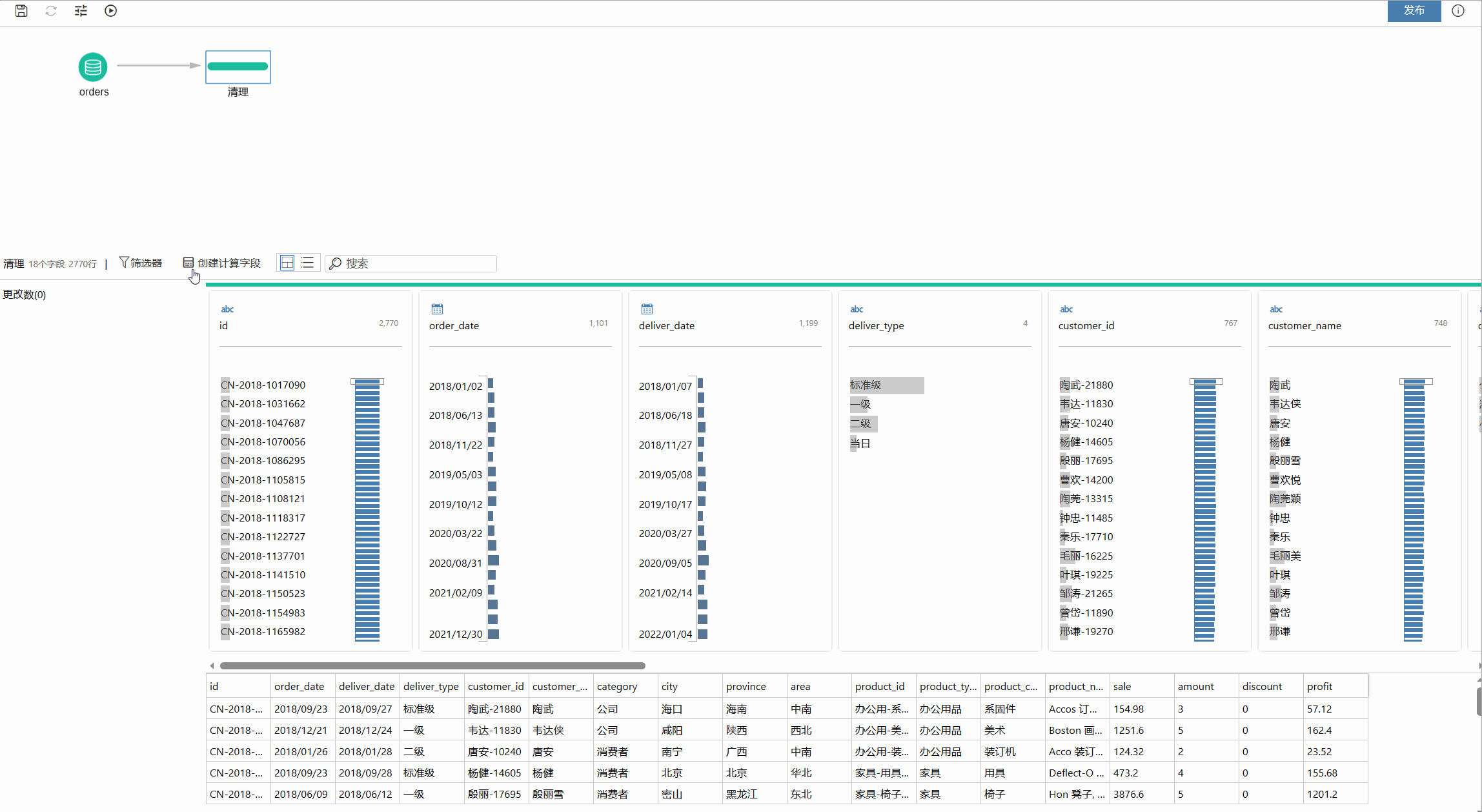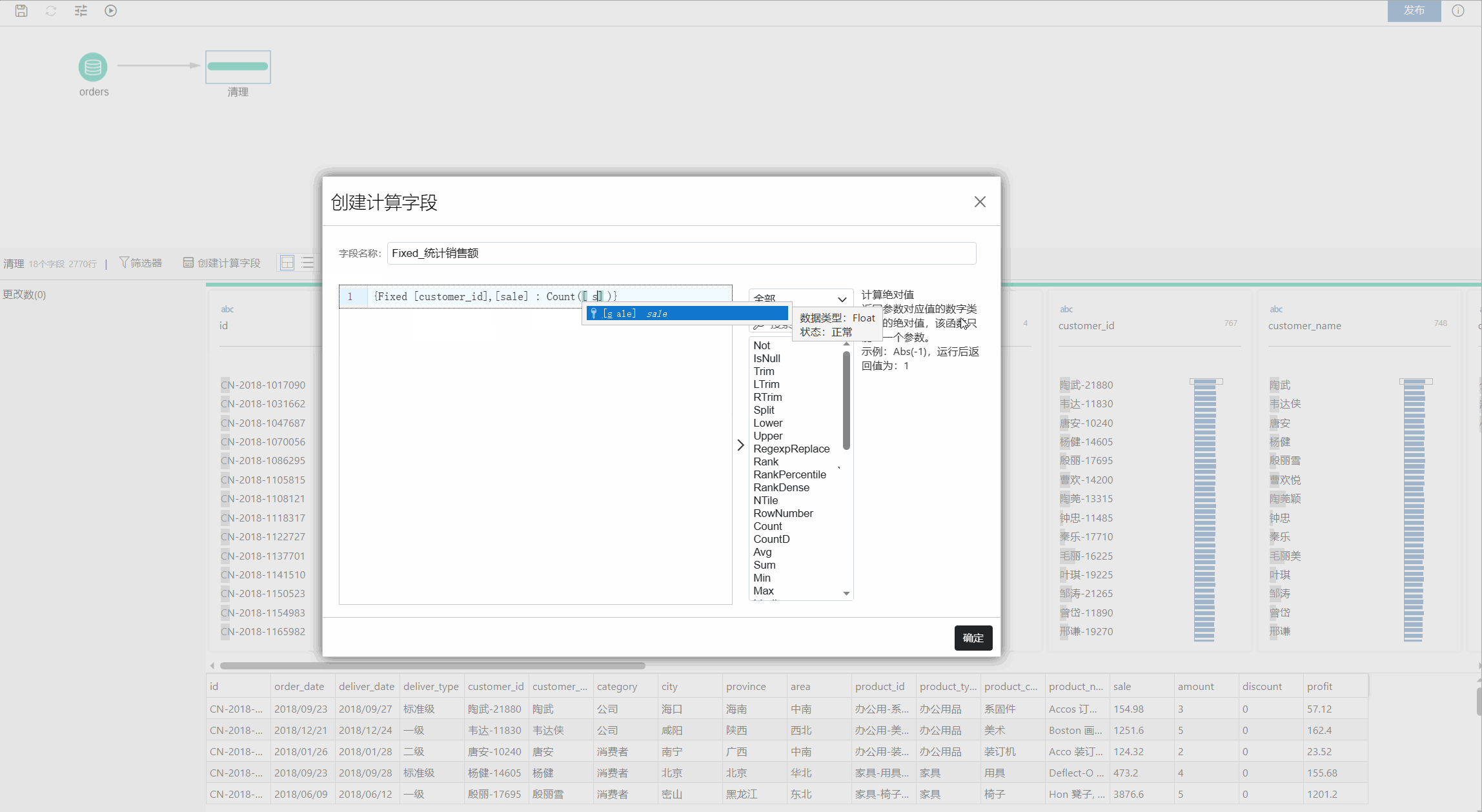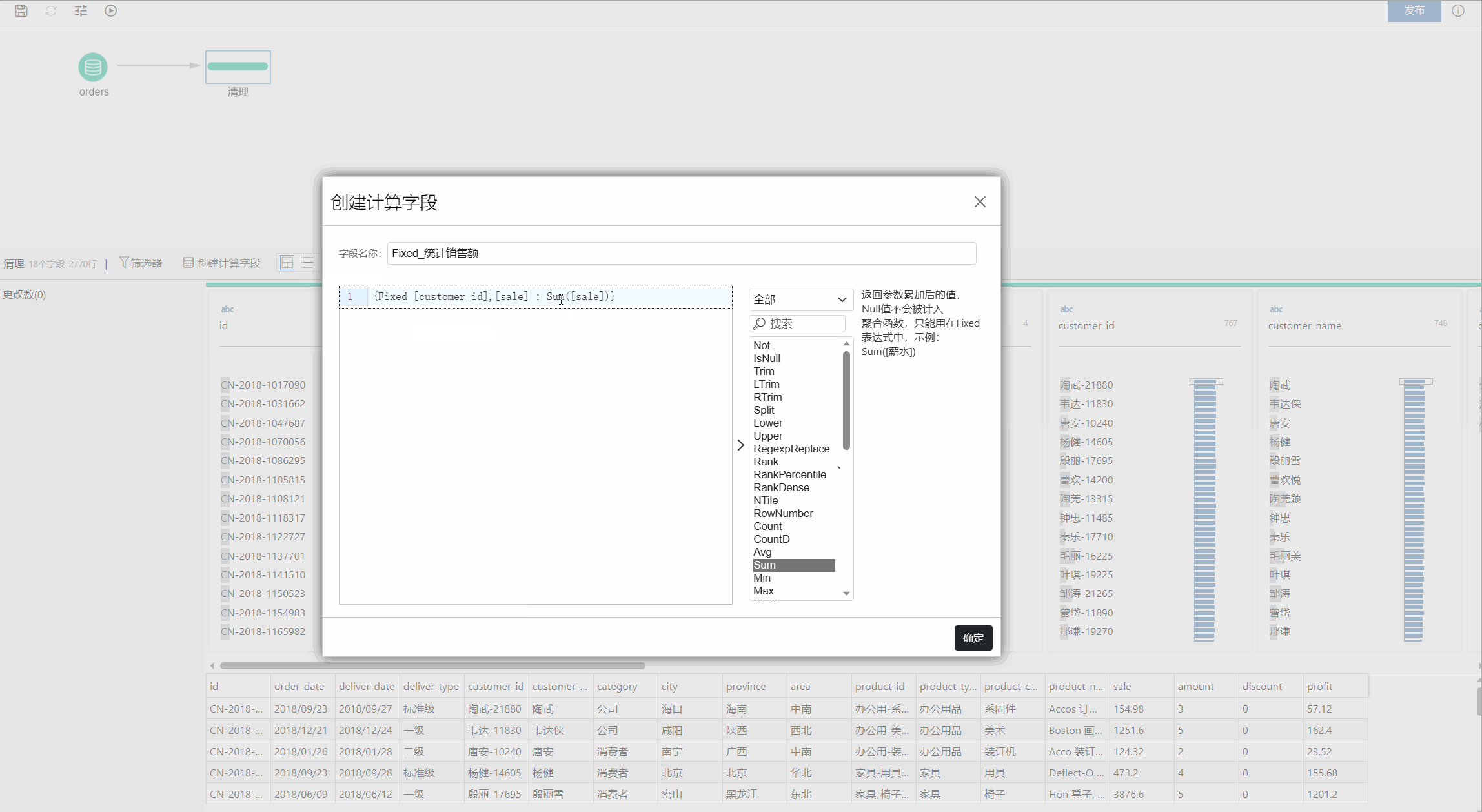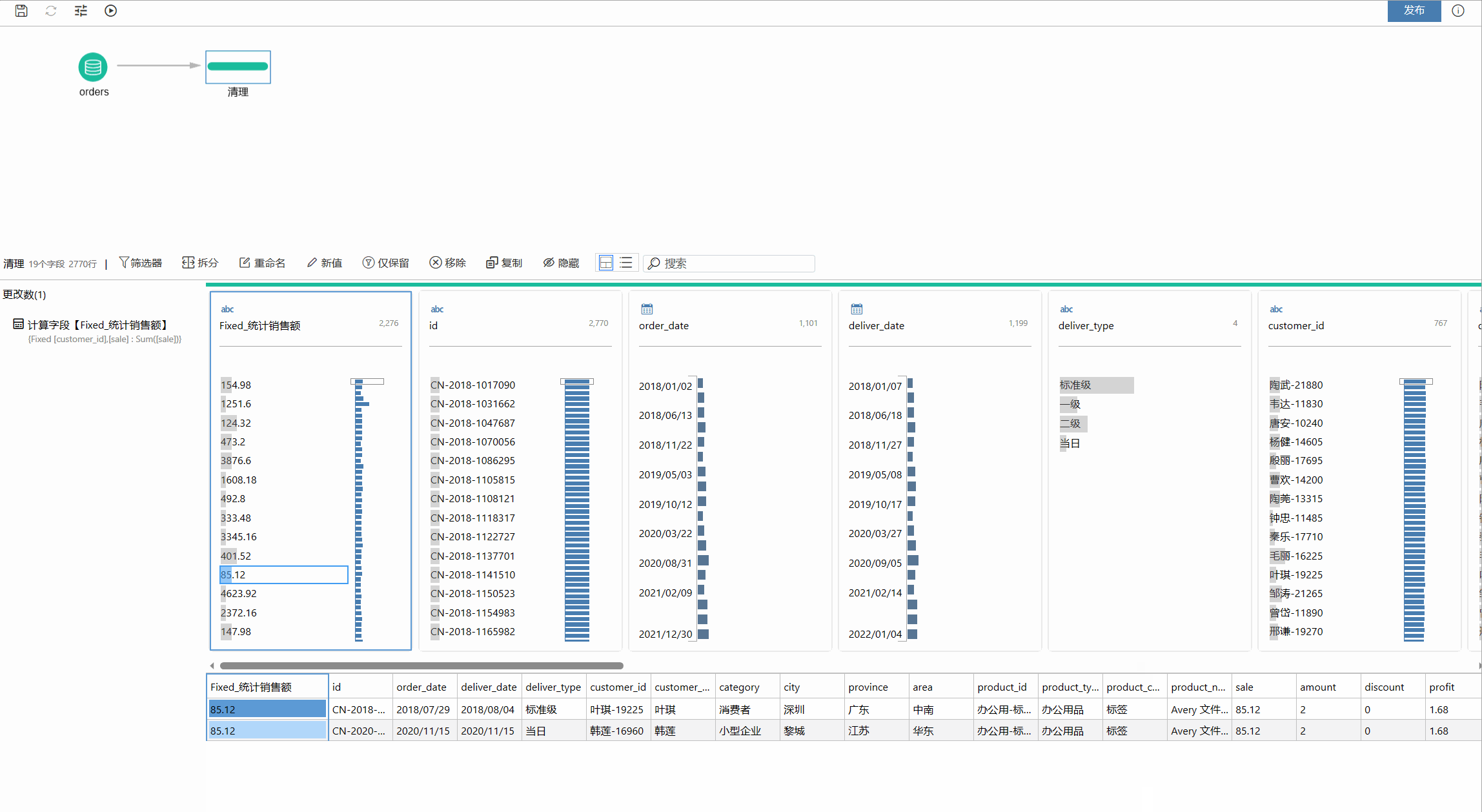
上图中,我们通过 Fixed 表达式,先对 customer_id 和 sale 字段进行分组,分组后的数据交由 sum 函数来统计销售额,所以产生的新列的值就是 customer_id 和 sale 字段分组后的销售额的累加值。
Partition
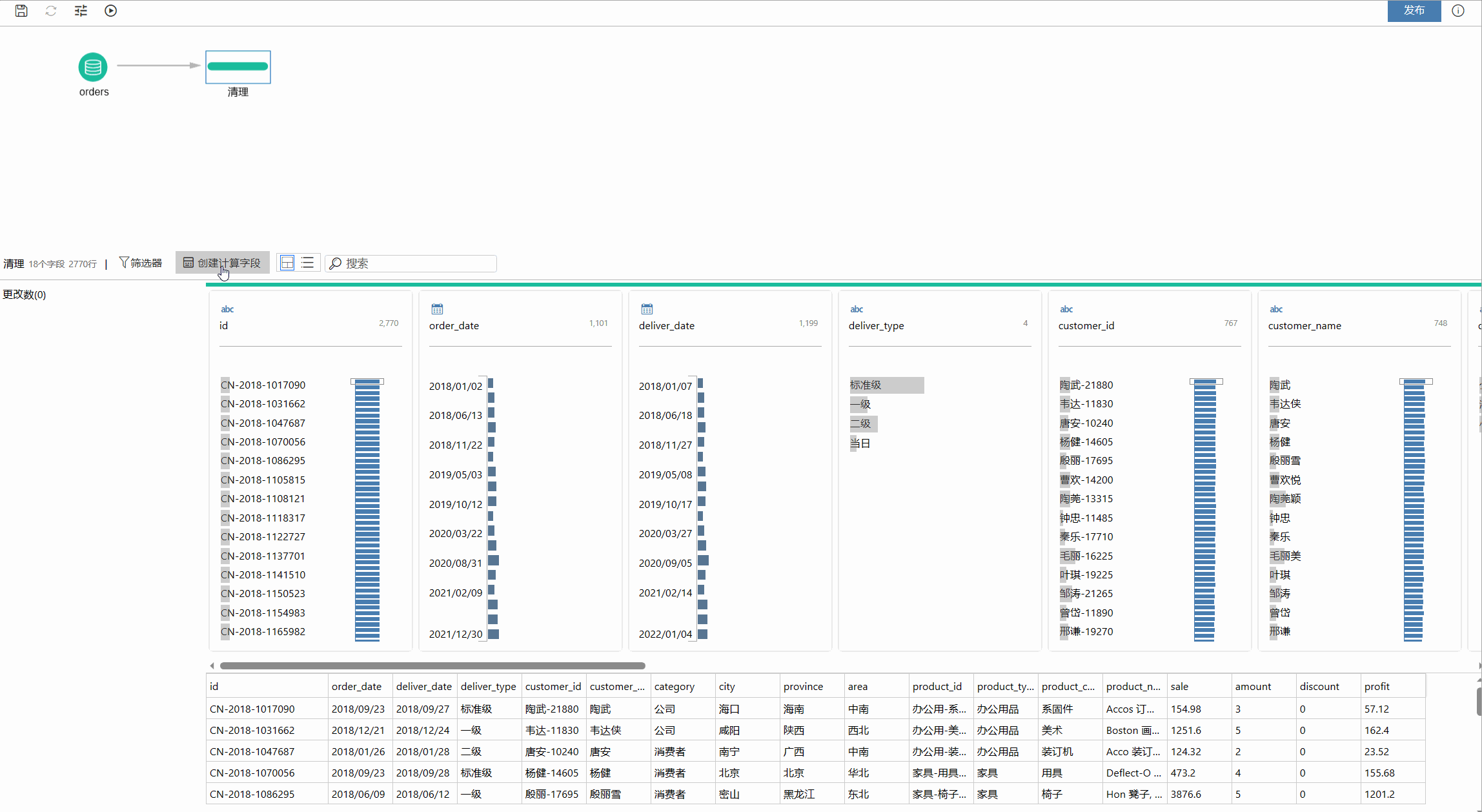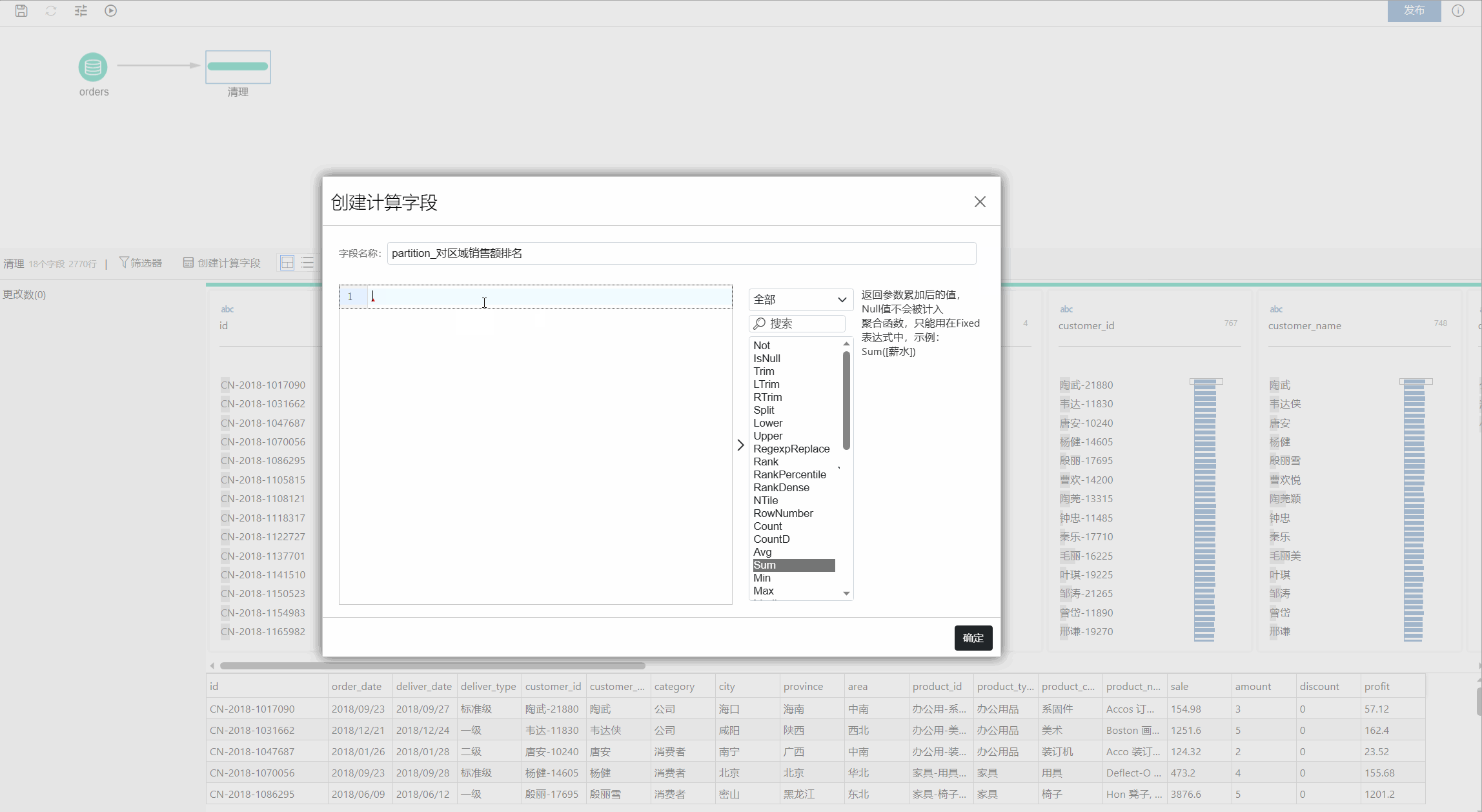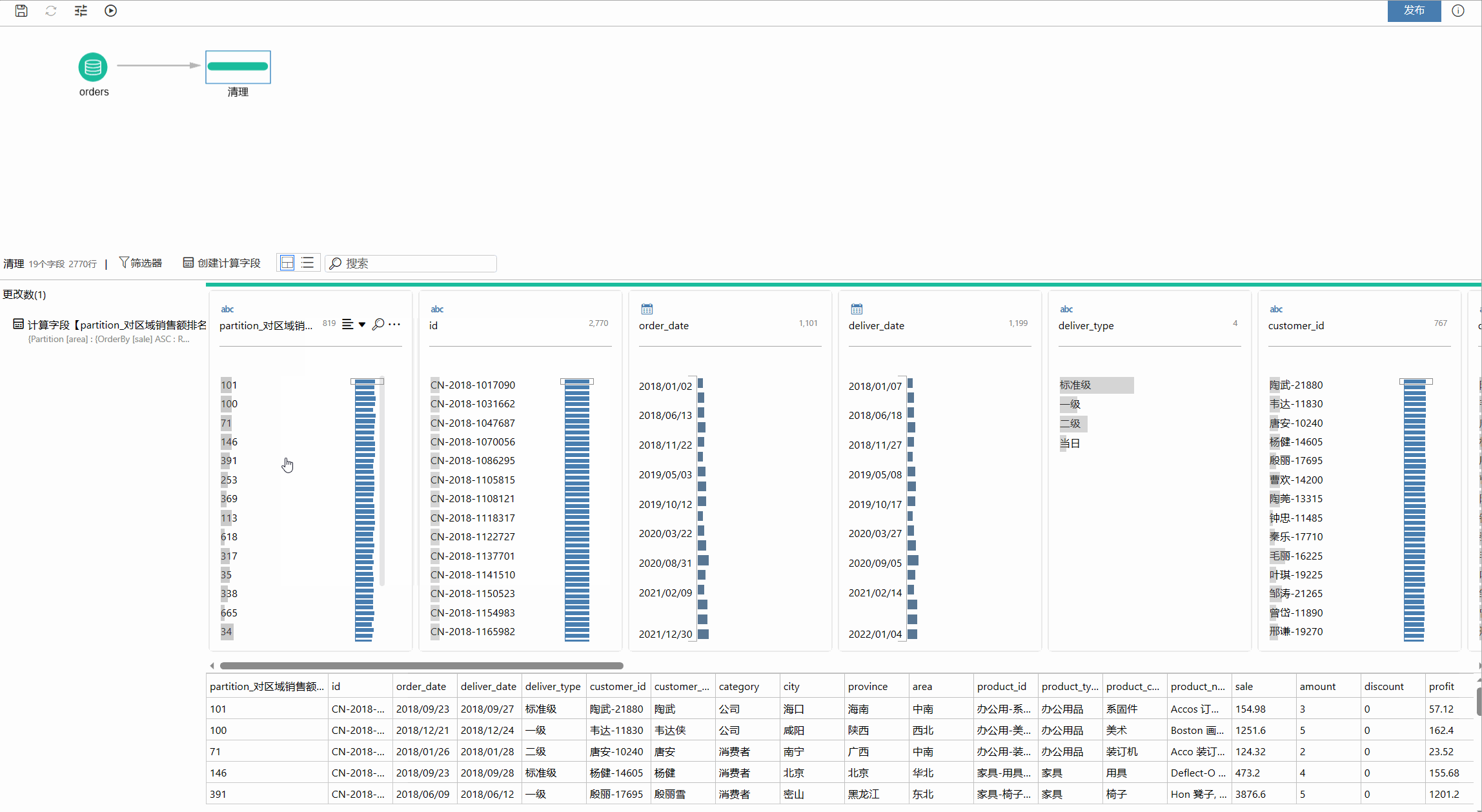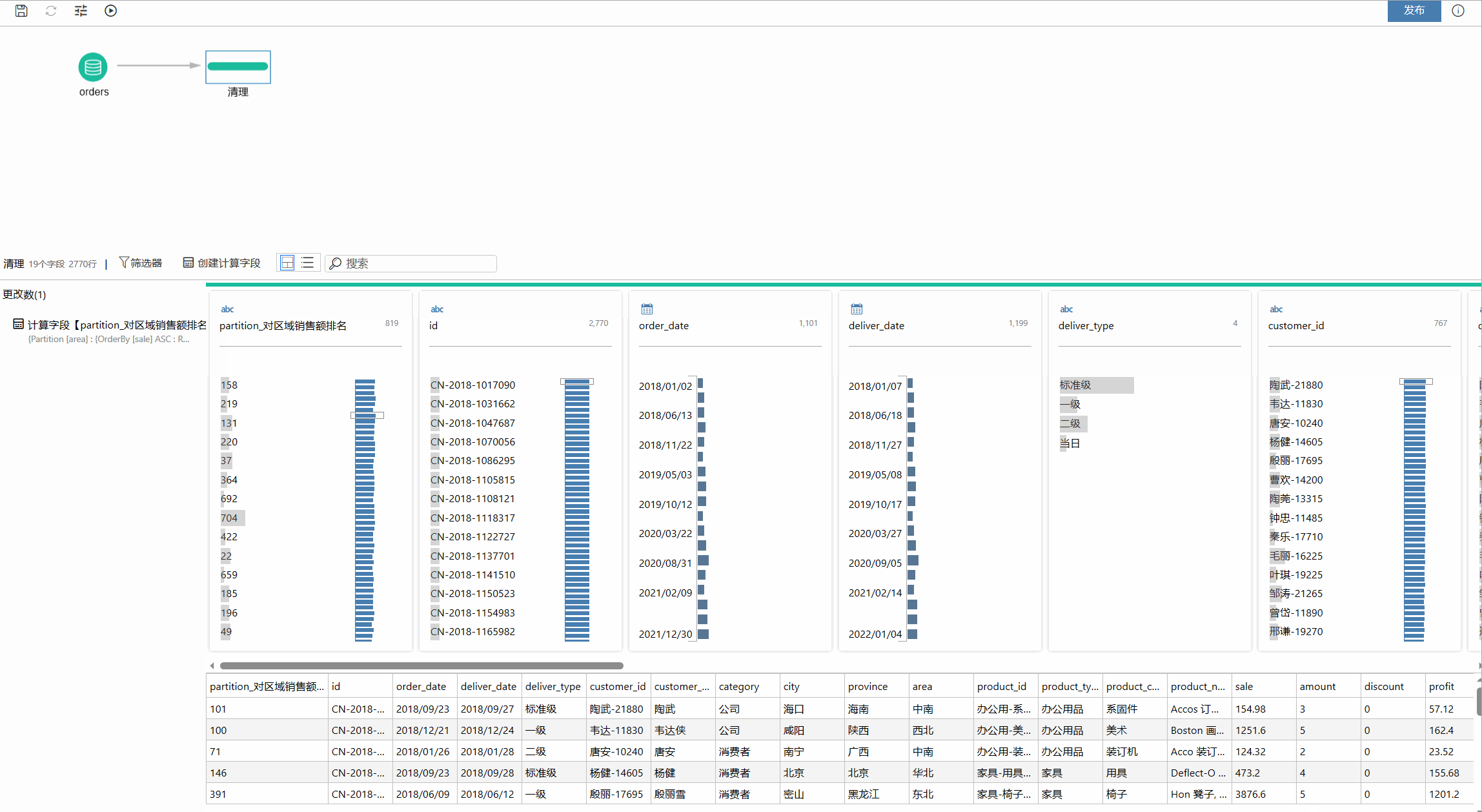
Partition 作用就是分区,要配合 OrderBy 表达式使用,能够对整个数据集中的所选行执行分区计算。例如,在将排名应用于所选行时,可以使用以下计算语法:
{Partition [field]: {OrderBy [field]: Rank() ASC}}
Partition [字段]
该部分是可选的。用于指定要其执行分区的行。可以指定多个字段,但如果要使用整个表,请省略函数的此部分,引擎将会将所有行视为分区。例如,{OrderBy [Sales] : Rank() ASC}
OrderBy [字段]
指定要用于生成排名序列的一个或多个字段,该部分为必须的。
分析函数
该部分为必须。上面使用的 Rank 就是一个分析函数,目前可用的分析函数有五个,如 Rank 用于排名、RowNumber 用于返回行号等。
ASC 或 DESC
该部分为必须,用于标识当前的 OrderBy 排序方式:ASC 为正序;DESC 为倒序。
创建示例
和 Fixed 表达式的结果一样,Partition 表达式也会产生新的结果,因此需要创建一个新的字段,可以点击工具栏上的创建计算字段实现,如下图所示:
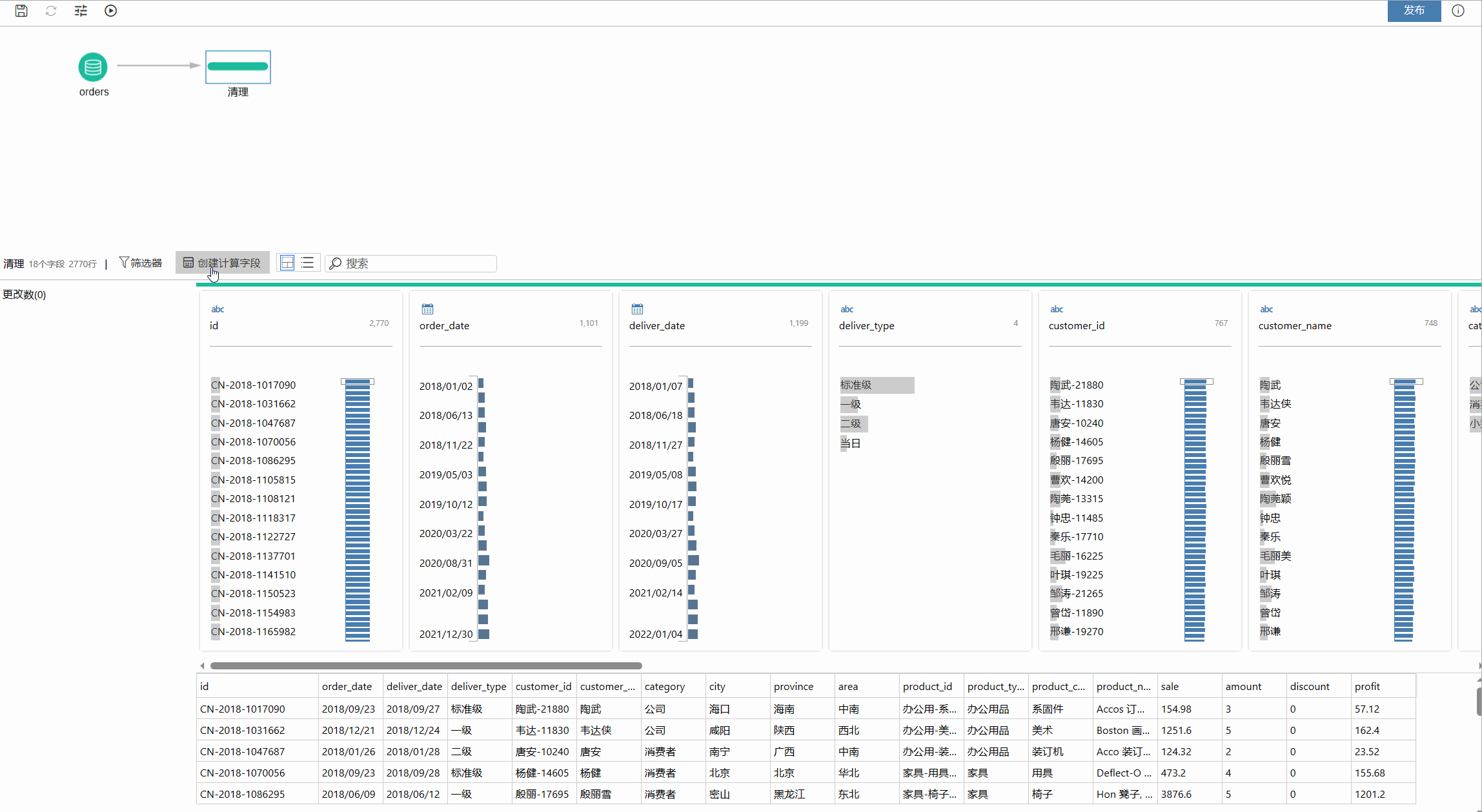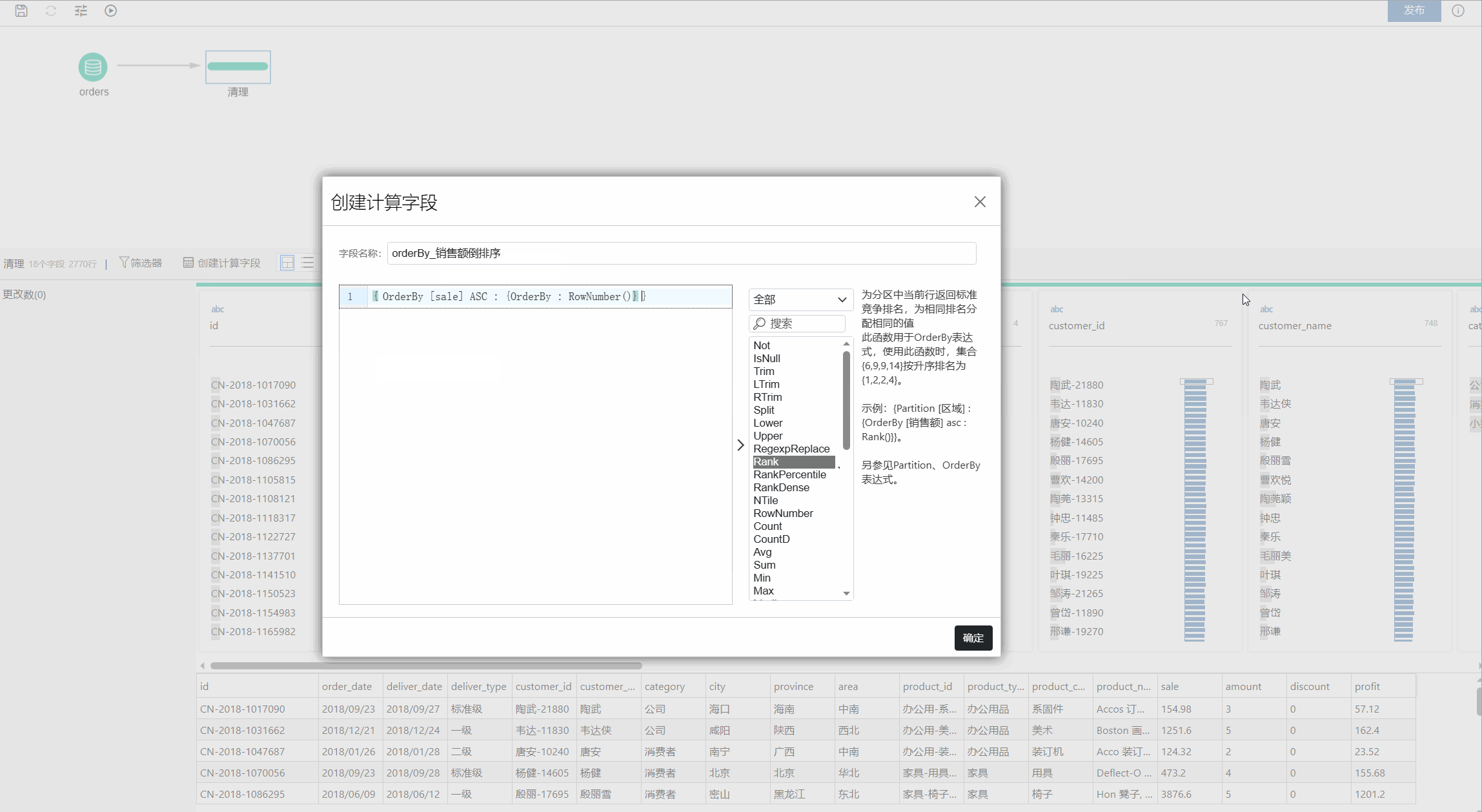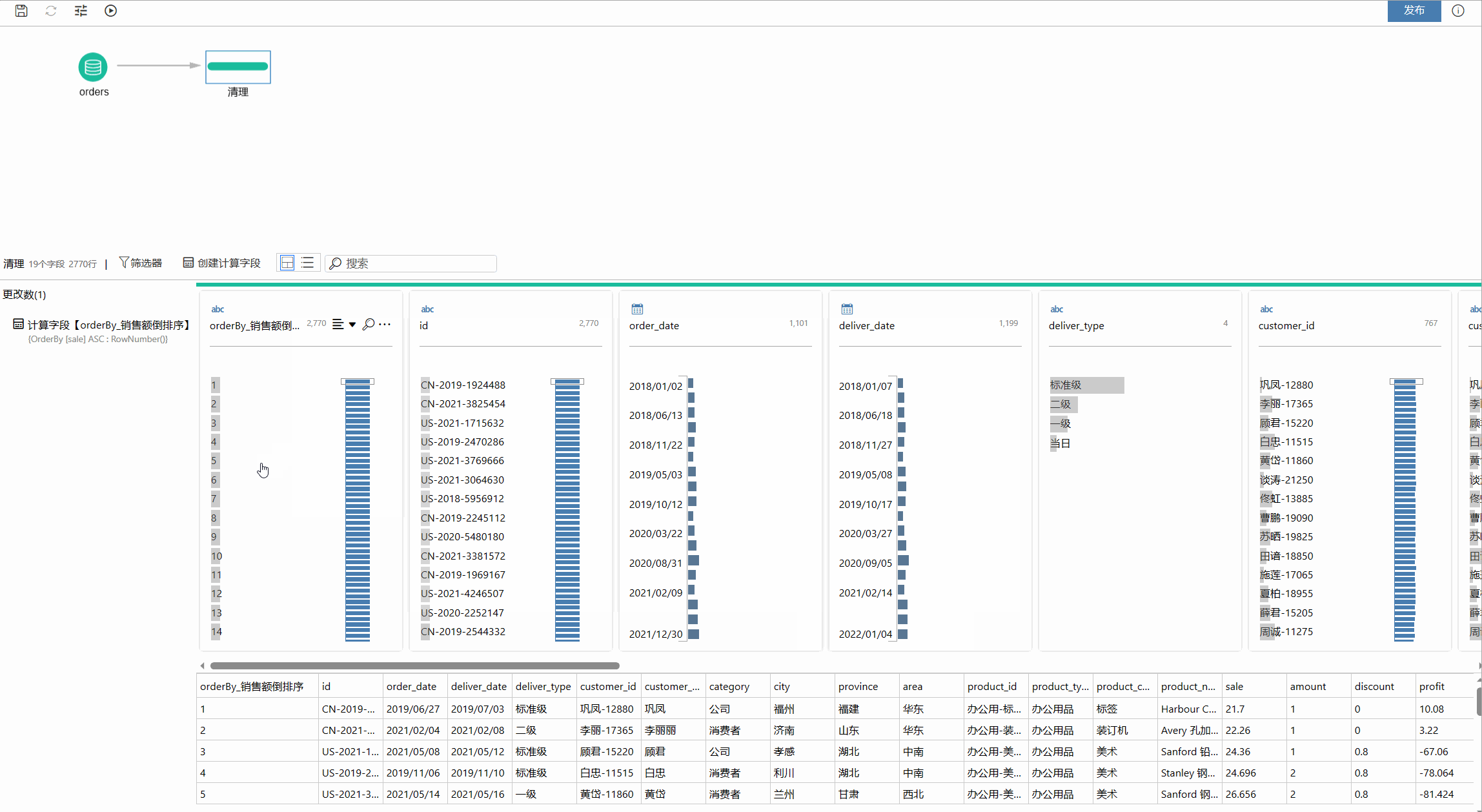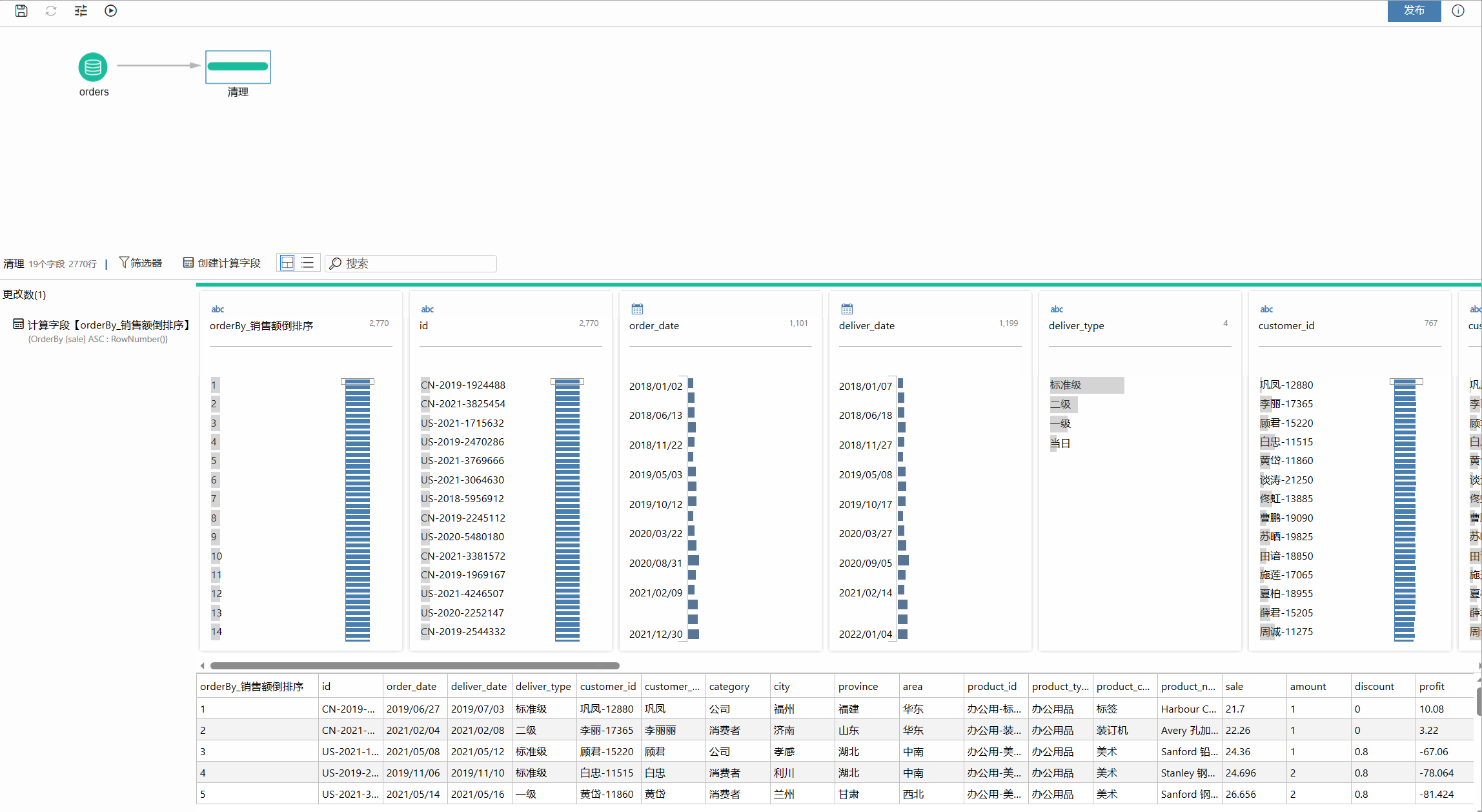
OrderBy
在介绍 Partition 表达式时,已涉及到 OrderBy;OrderBy 表达式即可以放在 Partition 表达式中使用,也可以单独使用。如果单独使用就是对整个数据集中的行进行排序,然后用分析函数进行计算,从而产生新的值。下面的例子中就针对销售额字段进行倒排序,然后利用 RowNumber 函数返回倒排序后的行号值。